💎 CRYSTAL Developer’s Diary #1: Simulation of CRYSTAL v2.0 operation using synthetic data generated with turboMaker and superMaker
October 8, 2025
upd: June 3
Contents:
1. Introduction
Simulation is needed for load testing with millions of users, posts, likes, hashtags, etc.
The purpose of load testing is to check the correctness and stability of the system under high load conditions at all levels:
- — Infrastructure: VPC, Nginx.
- — Server part: backend and database.
- — Client side: frontend.
2. Description of npm packages
To carry out the simulation, I created 4 npm packages with different functionality:
Superfast, multithreaded document generator for MongoDB, operating through CLI. Generates millions of documents at maximum speed, utilizing all CPU threads.
Data generator designed specifically for turboMaker. Generates random data: text, hashtags, words, email, id, url, array, boolean, etc.
CLI tool for extracting values of a specific field from a MongoDB collection and saving them into a target collection.
CLI tool for searching duplicate values in a MongoDB collection by a chosen field.
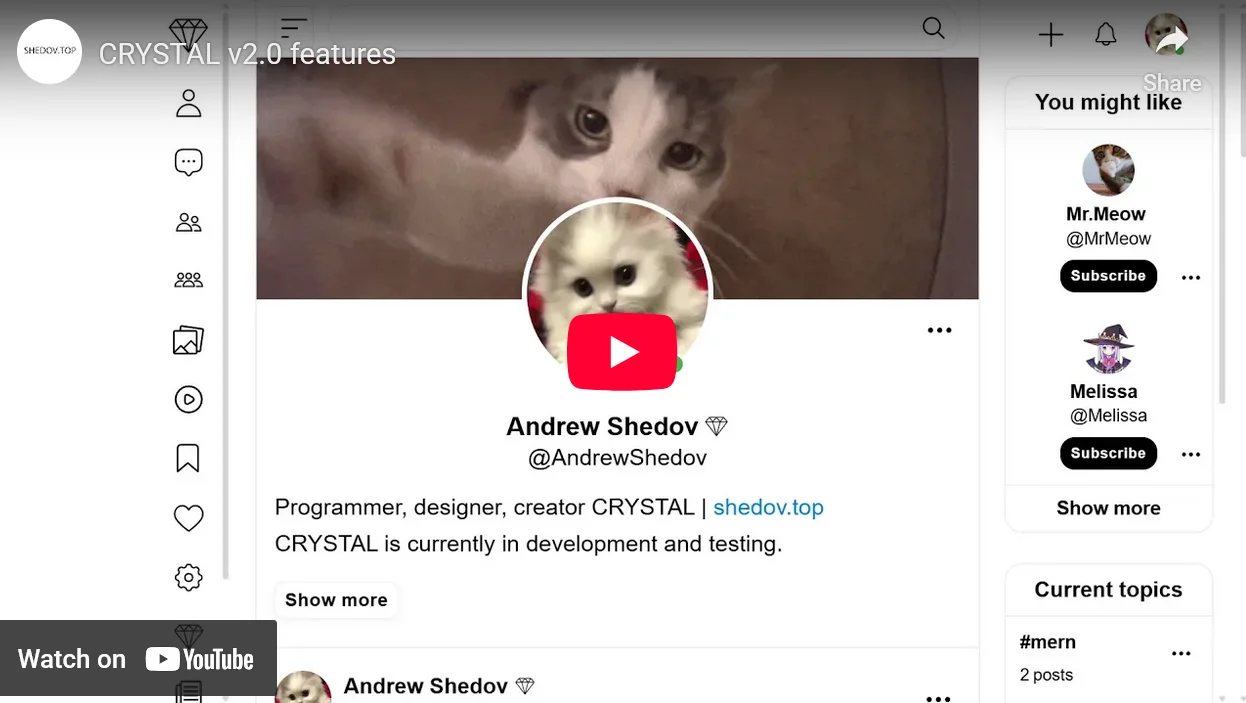
3. Video demonstrating the process of generating synthetic data and testing the functionality of CRYSTAL v2.0
4. Analysis of simulation and load testing results
Overall, the test with 1,000,000 posts demonstrated stable performance across the entire system and smooth infinite scrolling.
However, as expected, loading the list of hashtags (Current topics) turned out to be too slow due to a simplified hashtag extraction logic that was chosen earlier to speed up development.
To retrieve popular hashtags, an aggregation is performed using $unwind and $group, which significantly slows down loading:
hashtag.controller.js
import { PostModel } from "../../modules/post/index.js";
import {
handleServerError
} from "../../shared/helpers/index.js";
export const getHashtags = async (req, res) => {
const { limit } = req.query;
const max = parseInt(limit) || 6;
let result = await PostModel.aggregate([
{
$unwind: "$hashtags"
},
{
$group: {
_id: "$hashtags",
"hashtag": {
$first: "$hashtags"
},
"numberPosts": {
$sum: 1
}
}
},
{
$sort: {
"numberPosts": -1,
"hashtag": 1
}
},
{
$project: {
"_id": false
}
}
]).collation({ locale: 'en', strength: 2 }).limit(max).exec();
try {
return res.status(200).json(result);
} catch (error) {
handleServerError(res, error);
}
};
post.model.js
import mongoose from 'mongoose';
const PostSchema = new mongoose.Schema(
{
title: {
type: String,
default: ''
},
text: {
type: String,
default: ''
},
mainImageUri: String,
hashtags: {
type: Array,
default: [],
},
liked: {
type: Array,
default: [],
},
views: {
type: Number,
default: 0,
},
user: {
type: mongoose.Schema.Types.ObjectId,
ref: 'User',
required: true,
},
},
{
timestamps: true,
},
);
PostSchema.index({ createdAt: -1 });
export const PostModel = mongoose.model("Post", PostSchema);
5. New hashtag system
To speed up hashtag loading, a new system was introduced — hashtags are now stored in a separate collection called hashtags:
hashtag.model.js
import mongoose from 'mongoose';
const HashtagSchema = new mongoose.Schema(
{
name: {
type: String,
required: true,
trim: true,
lowercase: true,
},
postId: {
type: mongoose.Schema.Types.ObjectId,
ref: 'Post',
required: true,
},
postCreatedAt: {
type: Date,
required: true,
},
},
{
timestamps: true,
}
);
HashtagSchema.index({ name: 1, postCreatedAt: -1, postId: 1 }, { unique: true, collation: { locale: 'en', strength: 2 } });
HashtagSchema.index({ name: 1 });
HashtagSchema.index({ postId: 1 });
export const HashtagModel = mongoose.model('Hashtag', HashtagSchema);
Indexes:
1. index({ name: 1, postCreatedAt: -1, postId: 1 }, { unique: true, collation: { locale: 'en', strength: 2 } });
— Compound index for fast searching and cursor-based pagination.
2. index({ name: 1 });
— Used to count total posts for a specific hashtag (aggregation stage).
3. index({ postId: 1 });
— Enables fast deletion of all hashtags associated with a post.
Hashtag retrieval for the 'Current topics' component:
hashtag.controller.js
import { HashtagModel } from './hashtag.model.js';
import { handleServerError } from '../../shared/helpers/index.js';
export const getHashtags = async (req, res) => {
try {
const limit = parseInt(req.query.limit) || 6;
const result = await HashtagModel.aggregate([
// 1. Grouping and counting the number of posts for each hashtag
{ $group: { _id: "$name", quantity: { $count: {} } } },
// 2. Sort by: number first (DESC), then name (ASC)
{ $sort: { quantity: -1, _id: 1 } },
// 3. Limitation of the overall result
{ $limit: limit },
// 4. Projecting the result into the required format
{ $project: { name: "$_id", quantity: "$quantity", _id: 0 } }
]);
return res.status(200).json(result);
} catch (error) {
handleServerError(res, error);
}
};
Displaying posts by a specific hashtag and infinite scroll now use cursor pagination, which greatly improves performance compared to offset pagination — especially during deep scrolling:
post.controller.js
export const getPostsByHashtag = async (req, res) => {
try {
const limit = parseInt(req.query.limit) || 10;
const hashtag = req.query.tag.toLowerCase();
// 1. Creating a query and getting sorted ID (fast find with index)
let hashtagQuery = { name: hashtag };
if (req.query.cursor) {
const cursorDate = new Date(req.query.cursor);
if (isNaN(cursorDate.getTime())) {
return res.status(400).json({ message: 'Invalid cursor date' });
}
hashtagQuery.postCreatedAt = { $lt: cursorDate };
}
const hashtagDocs = await HashtagModel.find(hashtagQuery)
.sort({ postCreatedAt: -1 })
.limit(limit)
.select('postId postCreatedAt')
.lean()
.exec();
const postIds = hashtagDocs.map(doc => doc.postId);
if (postIds.length === 0) {
return res.status(200).json({ posts: [], nextCursor: null });
}
// 2. Creating a map (ID → index) for sorting
const idToIndexMap = new Map();
postIds.forEach((id, index) => idToIndexMap.set(id.toString(), index));
// 3. Performing a safe and fast '$in' on PostModel (unordered)
const fetchedPosts = await PostModel.find({ _id: { $in: postIds } })
.populate({
path: 'user',
select: ['name', 'customId', 'bio', 'status', 'creator', 'avatar', 'createdAt', 'updatedAt'],
})
.exec();
// 4. Final Sort (Fast O(N log N) on an array of 'limit' elements)
const resultPosts = fetchedPosts.sort((a, b) => {
const indexA = idToIndexMap.get(a._id.toString());
const indexB = idToIndexMap.get(b._id.toString());
return indexA - indexB;
});
// 5. Defining the next cursor
const nextCursor = hashtagDocs[hashtagDocs.length - 1].postCreatedAt.toISOString();
return res.status(200).json({ posts: resultPosts, nextCursor });
} catch (error) {
handleServerError(res, error);
}
};
To sort posts with a specific hashtag by creation date, denormalization was applied:
When creating or updating a post containing a hashtag, a denormalized field postCreatedAt is added to the corresponding hashtags document. This allows sorting and filtering posts by date directly in the hashtags collection, without additional queries to the posts collection.
In getPostsByHashtag, posts are retrieved from the hashtags collection using an efficient find() query, powered by the compound index { name: 1, postCreatedAt: -1 }, which lets MongoDB quickly locate the required records in sorted order.
post.controller.js
export const createPost = async (req, res) => {
try {
const combiningTitleAndText = (req.body?.title + ' ' + req.body.text).split(/[\s\n\r]/gmi).filter(v => v.startsWith('#'));
const hashtags = takeHashtags(combiningTitleAndText).map(tag => tag.replace(/^#/, '').toLowerCase());
if (hashtags.length > 30) {
return res.status(400).json({ message: 'Maximum 30 hashtags allowed' });
}
if (hashtags.some(tag => tag.length > 70)) {
return res.status(400).json({ message: 'Each hashtag must be 70 characters or less' });
}
const doc = new PostModel({
title: req.body?.title,
text: req.body.text,
mainImageUri: req.body.mainImageUri,
user: req.userId._id,
});
const mainImageUri = req.body.mainImageUri;
const text = req.body.text;
if (!(mainImageUri || (text.length >= 1))) {
return res.status(400).json({ message: 'Post should not be empty' });
}
// 1. Saving a post (returns ID and createdAt(postCreatedAt))
const post = await doc.save();
// 2. *** Hashtag logic ***
const postId = post._id;
const postCreatedAt = post.createdAt;
if (hashtags.length > 0) {
const hashtagDocs = hashtags.map((tag) => ({
name: tag.toLowerCase(),
postId,
postCreatedAt, // Denormalized field
}));
await HashtagModel.bulkWrite(
hashtagDocs.map((doc) => ({
insertOne: { document: doc },
})),
{ ordered: false }
);
}
// *** The end of hashtag logic ***
res.status(200).json(post);
} catch (error) {
handleServerError(res, error);
}
};
To avoid the 16 MB BSON limit when using the $in operator in getPostsByHashtag, the retrieval process was divided into two stages:
1. Fast Index Scan.
The hashtags collection is queried to fetch only the required post ID using .limit(N) (usually N = 10–20).
This produces a compact postIds array of fixed size containing only the necessary post references.
2. Safe query using $in.
The postIds array is then used to fetch complete post data from the posts collection.
Because the array size is small, the query executes safely and completely avoids exceeding the 16 MB BSON document limit.
6. Plans for further database structure improvements
In CRYSTAL v2.0, likes will be moved to a separate collection optimized for scalable reaction handling. Furthermore, Mongoose will be completely replaced by a native MongoDB driver, which will significantly improve the performance of CRUD operations, reduce latency during bulk requests, and improve overall database interaction efficiency.
Share




Comment on